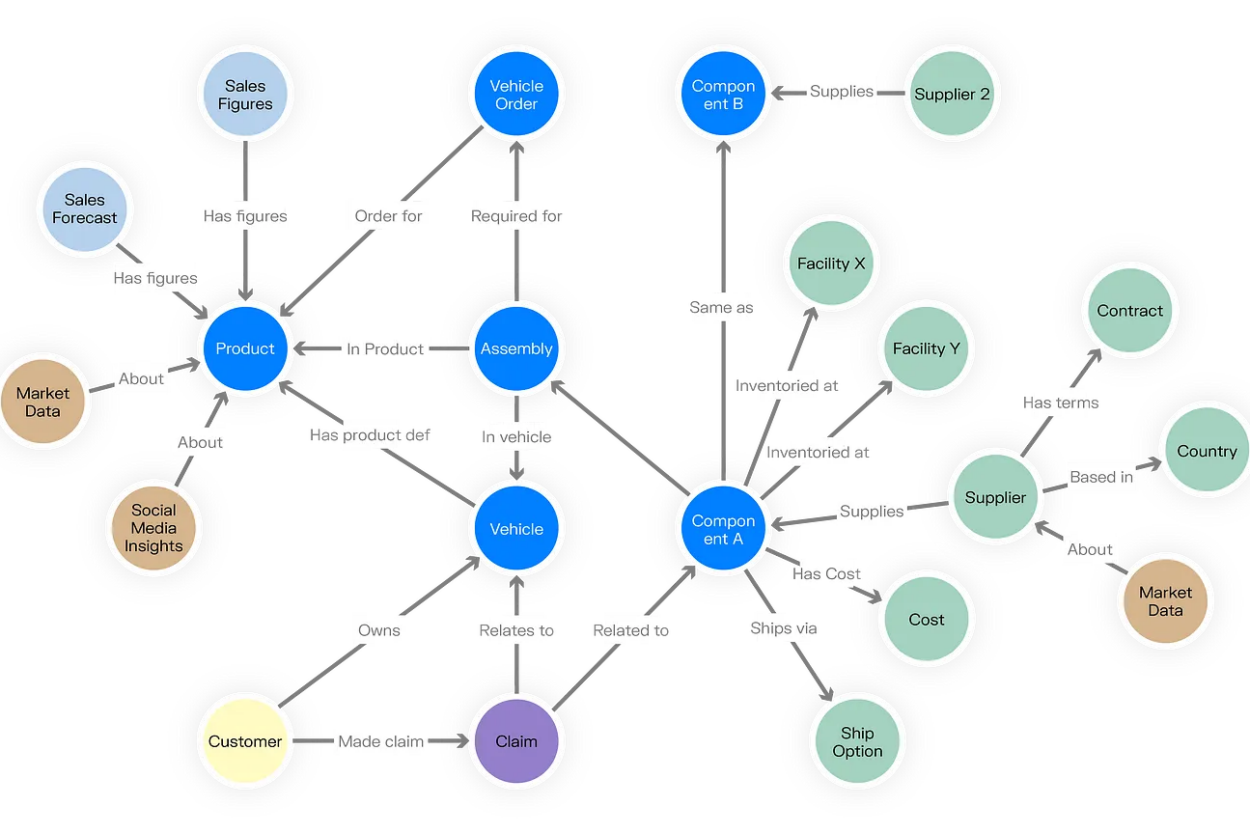
Knowledge Graph
Knowledge graphs transform complex information into interconnected networks of entities and relationships, mirroring how human brains connect concepts. Their growing adoption is linked to their enhancement of AI systems, particularly in LLMs and RAG pipelines.
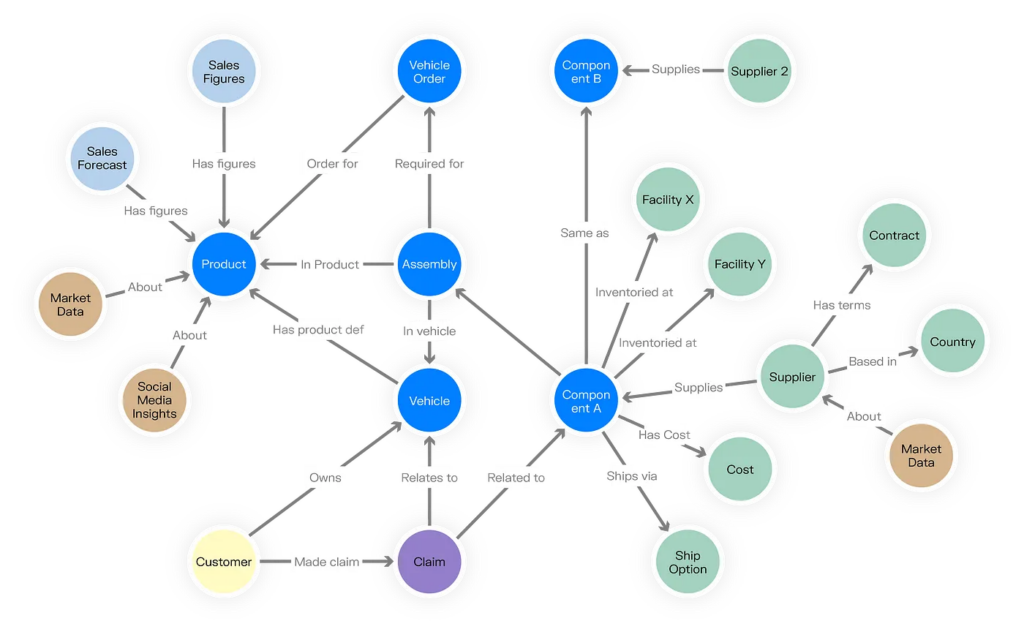
In RAG applications, knowledge graphs surpass traditional document retrieval by providing granular, relationship-rich information. Their ability to map cross-document connections creates a unified semantic layer, enabling more contextually aware retrieval and improved AI responses.
The typical knowledge graph construction involves document chunking, followed by LLM-based entity and relationship extraction from each chunk. This process identifies key entities and establishes connections between them, creating a structured knowledge representation.
While LLM-based knowledge graphs offer high accuracy, there are scenarios where a simpler, more cost-effective approach is needed. Using libraries like spaCy, we can create knowledge graphs without relying on LLMs, making it accessible for projects with limited resources or when quick prototyping is required. Though the accuracy might be lower, this approach provides a practical solution for organizations looking to experiment with knowledge graphs without the computational and financial overhead of LLM implementation.
Pipeline
Initial Setup and SpaCy Loading
First, we’ll import the necessary libraries and load SpaCy’s large English model, which includes word vectors for better language understanding. This sets up our foundation for natural language processing tasks.
import spacy
from typing import List, Dict, Tuple, Set
from collections import defaultdict
from rapidfuzz import fuzz
# Load the large English model which includes word vectors
nlp = spacy.load("en_core_web_lg")
# Example usage
text = """Bilbo Baggins celebrates his birthday and leaves the Ring to Frodo, his heir.
Gandalf suspects it is a Ring of Power and counsels Frodo to take it away."""
# Process the text with SpaCy
doc = nlp(text)Entity Extraction
Here we’ll identify and extract named entities from the text, ensuring we capture unique entities while preserving their original context and type information.
def extract_entities(doc) -> List[Dict]:
"""Extract and categorize named entities from a SpaCy doc."""
entities = []
unique_entities = set()
for ent in doc.ents:
if ent.text not in unique_entities:
entity_dict = {
'text': ent.text,
'type': ent.label_,
'start': ent.start_char,
'end': ent.end_char
}
entities.append(entity_dict)
unique_entities.add(ent.text)
return entities, unique_entities
# Example usage
entities, unique_entities = extract_entities(doc)Basic Relation Extraction
We’ll extract subject-verb-object relationships from the text, capturing how entities interact with each other through actions and connections.
def extract_basic_relations(doc) -> List[Dict]:
"""Extract subject-verb-object relations from a SpaCy doc."""
relations = []
for token in doc:
if token.pos_ == "VERB":
# Find subjects
subjects = []
for subj in token.lefts:
if subj.dep_ in ("nsubj", "nsubjpass"):
subjects.append(subj)
# Include conjunctions (e.g., "Sam and Frodo")
subjects.extend([child for child in subj.children
if child.dep_ == "conj"])
# Find objects
objects = []
for obj in token.rights:
if obj.dep_ == "dobj":
objects.append(obj)
# Include conjunctions
objects.extend([child for child in obj.children
if child.dep_ == "conj"])
elif obj.dep_ == "prep": # Handle prepositional objects
objects.extend([child for child in obj.children
if child.dep_ == "pobj"])
# Create relations for each subject-object pair
for subj in subjects:
for obj in objects:
relation = {
'subject': subj.text,
'relation': token.lemma_,
'object': obj.text,
'sentence': doc[token.sent.start:token.sent.end].text
}
relations.append(relation)
return relations
# Example usage
basic_relations = extract_basic_relations(doc)Pronoun Resolution
To improve the quality of our knowledge graph, we’ll implement a simple pronoun resolution system that maps pronouns to their most likely antecedent entities.
def resolve_pronouns(doc, entity_positions: List[Tuple]) -> Dict[str, str]:
"""Create a mapping of pronouns to their likely antecedents."""
pronouns = {"them", "it", "they", "who", "he", "she", "him", "his", "her", "their"}
pronoun_map = {}
for token in doc:
if token.text.lower() in pronouns:
# Find the nearest preceding entity
previous_entities = [ent for ent in entity_positions
if ent[1] < token.idx]
if previous_entities:
# Use the most recent entity as the antecedent
pronoun_map[token.text] = previous_entities[-1][0]
return pronoun_map
# Example usage
entity_positions = [(ent.text, ent.start_char, ent.end_char)
for ent in doc.ents]
pronoun_map = resolve_pronouns(doc, entity_positions)Fuzzy Entity Matching
To handle variations in entity names, we’ll implement fuzzy matching that can identify similar entities and standardize their references.
def fuzzy_match_entity(text: str, entities: set, threshold: float = 0.9) -> str:
"""Match text to the most similar entity using fuzzy matching."""
best_match = None
best_ratio = 0
text_lower = text.lower()
for entity in entities:
entity_lower = entity.lower()
# Try exact word matching first
if text_lower in entity_lower.split() or entity_lower in text_lower.split():
if len(text) > 3: # Avoid matching very short words
return entity
# Try partial string matching
if text_lower in entity_lower or entity_lower in text_lower:
if len(text) > 3:
return entity
# Calculate token sort ratio for word order differences
ratio = fuzz.token_sort_ratio(text_lower, entity_lower) / 100.0
# If needed, try partial ratio for substring matches
if ratio < threshold:
ratio = fuzz.partial_ratio(text_lower, entity_lower) / 100.0
if ratio > threshold and ratio > best_ratio:
best_match = entity
best_ratio = ratio
return best_match if best_match else text
# Example usage
test_text = "Baggin" # Misspelled name
matched_entity = fuzzy_match_entity(test_text, unique_entities)Extracting Relations From Text
Finally, we’ll combine all our components into a single pipeline that processes text and generates a complete knowledge graph representation.
def process_text_pipeline(text: str) -> Dict:
"""Process text through the complete pipeline."""
# Step 1: Process with SpaCy
doc = nlp(text)
# Step 2: Extract entities
entities, unique_entities = extract_entities(doc)
# Step 3: Get entity positions for pronoun resolution
entity_positions = [(ent['text'], ent['start'], ent['end'])
for ent in entities]
# Step 4: Create pronoun mapping
pronoun_map = resolve_pronouns(doc, entity_positions)
# Step 5: Extract basic relations
relations = extract_basic_relations(doc)
# Step 6: Resolve pronouns and fuzzy match entities in relations
resolved_relations = []
for rel in relations:
resolved_rel = rel.copy()
# Resolve subject
if rel['subject'].lower() in pronoun_map:
resolved_rel['subject'] = pronoun_map[rel['subject'].lower()]
else:
resolved_rel['subject'] = fuzzy_match_entity(
rel['subject'], unique_entities
)
# Resolve object
if rel['object'].lower() in pronoun_map:
resolved_rel['object'] = pronoun_map[rel['object'].lower()]
else:
resolved_rel['object'] = fuzzy_match_entity(
rel['object'], unique_entities
)
resolved_relations.append(resolved_rel)
return {
'entities': entities,
'relations': resolved_relations,
'pronoun_map': pronoun_map
}
# Example usage of the complete pipeline
text = """
Bilbo Baggins celebrates his birthday and leaves the Ring to Frodo, his heir.
Gandalf suspects it is a Ring of Power and counsels Frodo to take it away.
"""
result = process_text_pipeline(text)Creating the Knowledge Graph
First, we’ll create a class to handle our knowledge graph operations using NetworkX:
import networkx as nx
import matplotlib.pyplot as plt
from typing import List, Dict
import logging
class LORKnowledgeGraph:
def __init__(self):
"""Initialize the NetworkX graph with multi-directed edges."""
self.G = nx.MultiDiGraph()
logging.basicConfig(level=logging.INFO)
self.logger = logging.getLogger(__name__)
def create_entity_node(self, entity: str):
"""Create a node with sanitized label."""
label = entity.replace(' ', '_').replace('-', '_').replace("'", '')
if not label[0].isalpha():
label = 'N_' + label
self.G.add_node(label, name=entity)
def create_relationship(self, subject: str, relation: str, object: str):
"""Create a relationship between two nodes."""
subject_label = subject.replace(' ', '_').replace('-', '_').replace("'", '')
object_label = object.replace(' ', '_').replace('-', '_').replace("'", '')
if not subject_label[0].isalpha():
subject_label = 'N_' + subject_label
if not object_label[0].isalpha():
object_label = 'N_' + object_label
relation_type = relation.upper().replace(' ', '_')
self.G.add_edge(subject_label, object_label, relation=relation_type)
def build_from_relations(self, relations: List[Dict]):
"""Build the graph from extracted relations."""
for relation in relations:
self.create_entity_node(relation['subject'])
self.create_entity_node(relation['object'])
self.create_relationship(
relation['subject'],
relation['relation'],
relation['object']
)Now, let’s extend our pipeline to process multiple text segments and build a knowledge graph:
def process_multiple_texts(texts: List[str]) -> nx.MultiDiGraph:
"""Process multiple text segments and create a knowledge graph."""
# Initialize the knowledge graph
kg = LORKnowledgeGraph()
# Process each text segment
for text in texts:
# Process text through our existing pipeline
result = process_text_pipeline(text)
# Add extracted relations to the knowledge graph
kg.build_from_relations(result['relations'])
return kg.G
def visualize_knowledge_graph(G: nx.MultiDiGraph, figsize=(16, 12)):
"""Visualize the knowledge graph."""
plt.figure(figsize=figsize)
# Calculate node sizing based on degree centrality
degrees = dict(G.degree())
node_sizes = [1500 + (degrees[node] * 100) for node in G.nodes()]
# Use Graphviz layout for better visualization
pos = nx.nx_agraph.graphviz_layout(G, prog='neato')
# Draw the graph with curved edges and node labels
nx.draw_networkx_edges(G, pos,
edge_color='gray',
alpha=0.4,
arrows=True,
connectionstyle='arc3,rad=0.2')
nx.draw_networkx_nodes(G, pos,
node_color='lightblue',
node_size=node_sizes,
alpha=0.7)
# Add labels
node_labels = nx.get_node_attributes(G, 'name')
edge_labels = nx.get_edge_attributes(G, 'relation')
nx.draw_networkx_labels(G, pos, node_labels, font_size=8)
nx.draw_networkx_edge_labels(G, pos, edge_labels, font_size=6)
plt.title("Knowledge Graph Visualization")
plt.axis('off')
return pltFinal Result
Here’s what the final result on multiple chunks of text from Lord of the Rings looks like:
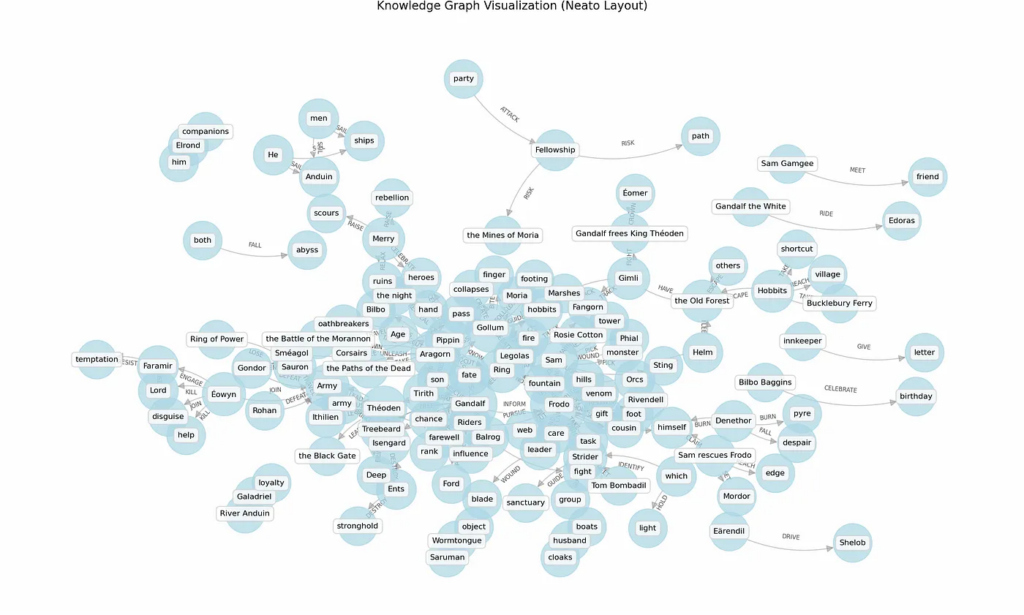
Conclusion
This lightweight approach to knowledge graph construction demonstrates that valuable semantic networks can be created without relying on large language models. While LLM-based approaches may offer higher accuracy and more nuanced relationship extraction, the combination of SpaCy, fuzzy matching, and basic NLP techniques provides a robust foundation for organizations looking to experiment with knowledge graphs. This method not only offers significant cost savings but also provides greater transparency and control over the extraction process. As knowledge graphs continue to evolve as critical components of modern AI systems, having accessible, LLM-free alternatives ensures that organizations of all sizes can harness the power of structured knowledge representation for their specific use cases.

