What is tokenization?
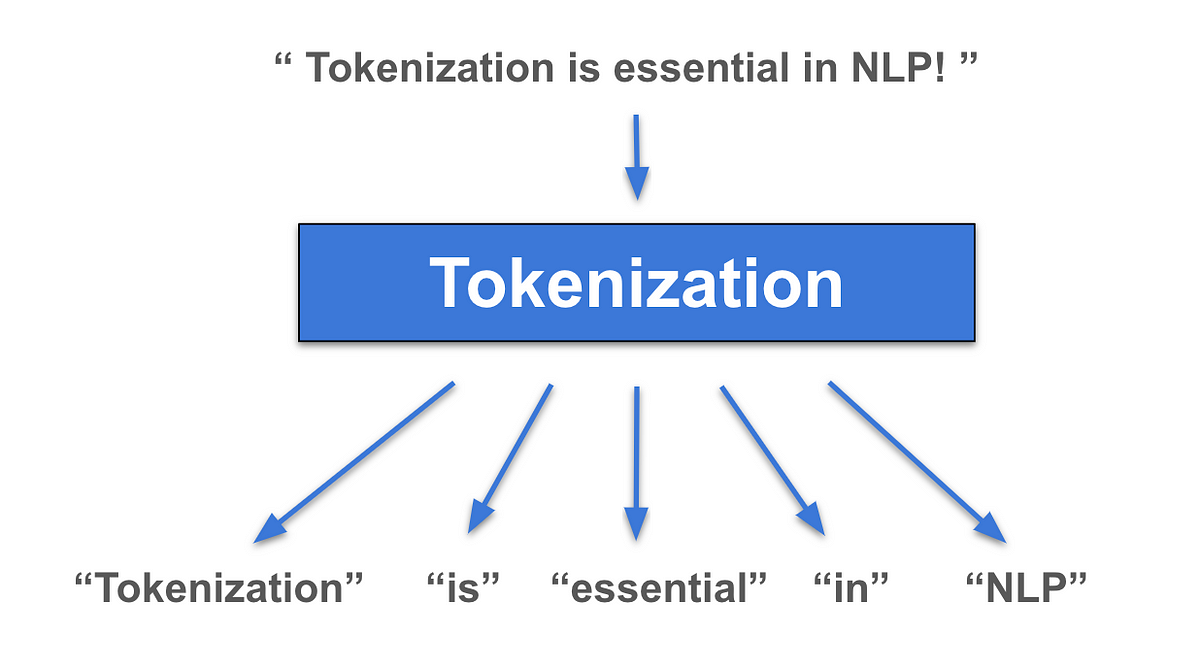
Tokenization is the process of breaking down text into smaller units called tokens, which can be words, subwords, or individual characters. These tokens represent the smallest meaningful elements of a text that a language model can process. For instance, the sentence ”Hello, world!” might be tokenized into [“Hello”, “,”, “world”, “!”]. This process simplifies the text, enabling the model to handle it as manageable data chunks.
In workflows for LLM pre-training and inference, each token is mapped to a unique integer after tokenization. These integers serve as indices for a lookup table containing vector representations of the tokens. These vectors are then fed into the language model as inputs corresponding to their respective tokens.
Need of tokenization
Imagine you want to pre-train your own language model using 10 GB of text data. The challenge is that machine learning models, including language models, can only work with numerical data, not raw text. This is where tokenization becomes essential.
Tokenization transforms text into smaller units called tokens, and each token is assigned a unique integer identifier. These integers are then converted into numerical vectors, which the language model processes. The model takes this vectorized input, performs computations, and produces output in the form of integers, which are later converted back into text.
Without tokenization, it would be impossible for language models to handle raw textual data effectively. It serves as the crucial bridge between text and the numerical computations that drive these models.
What Is a tokenizer?
A tokenizer is a tool that prepares text for processing by breaking it into smaller units called tokens, an essential step in natural language processing (NLP) tasks such as text classification, machine translation, and question answering.
Here’s what tokenizers do:
– Text segmentation: Tokenizers decompose unstructured text into manageable units, which can be words, subwords, or characters.
– Conversion to numerical form: They translate tokens into numerical data that machine learning models can understand and process.
– Meaningful representation: Tokenizers aim to identify the most meaningful and compact representation of the text for the model, ensuring it captures essential information in an efficient format.
Types of Tokenizers

1. Word-Level Tokenizers
These tokenizers split text into individual words or phrases, typically using spaces or punctuation.
Example: ”I love NLP” → [“I”, “love”, “NLP”]
Pros: Simple and works well for languages with space-separated words like English.
Cons: Struggles with out-of-vocabulary (OOV) words and is inefficient for languages without clear word boundaries (e.g., Chinese).
2. Subword Tokenizers
These break words into smaller meaningful units or subwords to balance vocabulary size and representation.
– Byte Pair Encoding (BPE): Iteratively merges frequent character pairs into subwords.
Example: ”unbelievable” → [“un”, “believ”, “able”]
– WordPiece: Optimized for probabilistic models (used in BERT).
Example: ”playground” → [“play”, “##ground”]
– SentencePiece: Does not require pre-tokenization and operates on raw text.
Example: ”Hello” → [“_Hello”]
Pros: Reduces vocabulary size and handles OOV words better by splitting them into meaningful subwords.
Cons: Requires pre-training on specific datasets to learn optimal splits.
3. Character-Level Tokenizers
These treat each character as an individual token.
Example: ”hello” → [“h”, “e”, “l”, “l”, “o”]
Pros: No OOV issues and ideal for morphologically complex languages or noisy text.
Cons: Produces longer sequences, increasing computational costs and reducing efficiency.
4. Byte-Level Tokenizers
These split text into bytes, treating each byte (numerical representation of a character) as a token.
Example: ”hello” → [104, 101, 108, 108, 111] (ASCII values).
Pros: Supports all languages without modification and handles special characters seamlessly.
Cons: Results in longer sequences compared to word or subword tokenizers.
5. Token-Free Models
These operate directly on text without predefined tokenization, often representing text at the character or byte level.
Example: Works directly with input like ”hello”.
Pros: Avoids the complexities of vocabulary design and tokenization, making it suitable for multilingual or noisy datasets.
Cons: Requires specialized models to efficiently process raw input.
6. Hybrid Tokenizers
These combine multiple approaches, such as word-level and subword-level tokenization, or byte-level with character-level tokenization.
Example: SentencePiece with BPE fallback to character-level for rare words.
Pros: Balances efficiency with representation quality, offering flexibility for diverse inputs.
Cons: More complex to implement and tune.
Choosing the right tokenizer depends on the language, application, and quality of the input text. For modern large language models, subword tokenizers are often the standard due to their balance of efficiency and generalization capabilities. For noisy or unconventional text, character-level or byte-level tokenizers (e.g., SHIBA) are robust alternatives.
What is Shiba?
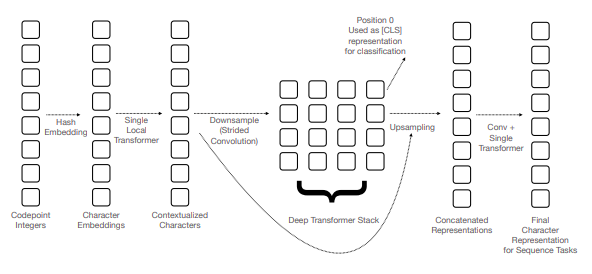
SHIBA is an approximate reimplementation of CANINE[1], built using raw PyTorch and pre-trained on the Japanese Wikipedia corpus with random span masking. For those unfamiliar with CANINE, it is a highly efficient character-level language model, roughly four times more efficient than BERT. Similarly, SHIBA operates at the character level, focusing on efficiency and effectiveness.
The name “SHIBA” is inspired by the Shiba Inu, a well-known Japanese dog breed, aligning with the naming convention of its predecessor.
Performance of Shiba
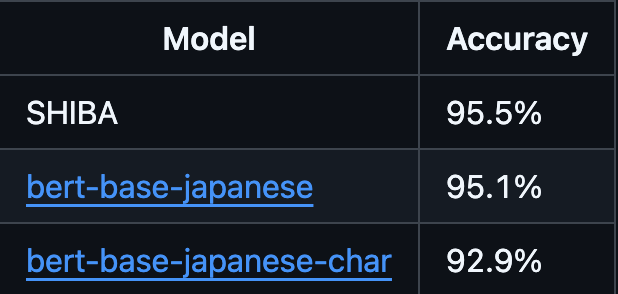
Task 1: Classification
The first evaluation task involved text classification on the *Livedoor News Corpus*, utilizing as much text from each article as could fit into the model in a single pass.
Task 2: Word Segmentation
The second task focused on word segmentation using the *UD Japanese GSD corpus*.

While SHIBA slightly lags behind MeCab, which excels in word segmentation due to its dictionary-based approach, SHIBA is expected to perform better on noisy or unconventional text where dictionary-based tools like MeCab struggle.
How to encode and decode text using shiba
Here’s a step-by-step guide to implement the provided code for processing PDF text using the SHIBA model. You can copy and paste this directly into your Medium article.
Step 1: Install Required Libraries
Start by installing the required libraries. You’ll need `PyPDF2` for extracting text from PDFs and `shiba-model` for using the SHIBA model. Run the following command:
pip install PyPDF2 shiba-model
Step 2: Import Libraries and Initialize the SHIBA Model
Import the necessary modules and initialize the SHIBA model and its tokenizer. SHIBA uses a pretrained character-level model, so we also disable dropout to ensure consistent outputs.
import PyPDF2
from shiba import Shiba, CodepointTokenizer, get_pretrained_from_hub
# Load SHIBA model and tokenizer
shiba_model = Shiba()
shiba_model.load_state_dict(get_pretrained_from_hub())
shiba_model.eval() # Disable dropout
tokenizer = CodepointTokenizer()– PyPDF2: Used to read and extract text from PDF files.
– Shiba: The main model for processing character-level text.
– CodepointTokenizer: Tokenizes text at the character level.
Step 3: Extract Text from PDF
Define a function to extract text from a PDF file using PyPDF2. This function reads the PDF, iterates through its pages, and extracts text.
def extract_text_from_pdf(pdf_path):
“””Extract text from a given PDF file.”””
text = “”
with open(pdf_path, “rb”) as file:
reader = PyPDF2.PdfReader(file)
for page in reader.pages:
text += page.extract_text()
return text
Step 4: Split Text into Chunks
Since SHIBA has a maximum input length, split the extracted text into smaller chunks. This function takes the full text and splits it into segments of a specified maximum length.
def split_text(text, max_length=1800):
“””Split text into chunks within the max length allowed by SHIBA.”””
return [text[i:i + max_length] for i in range(0, len(text), max_length)]
Step 5: Process Text with SHIBA
Process the text chunks using SHIBA. Each chunk is tokenized, encoded, and passed through the model to obtain outputs.
def process_pdf_with_shiba(pdf_path):
# Extract and clean text from PDF
text = extract_text_from_pdf(pdf_path)
# Split text into manageable chunks
text_chunks = split_text(text)
all_outputs = []
encoded_chunks = []
for i, chunk in enumerate(text_chunks):
# Encode each chunk
encoded = tokenizer.encode_batch([chunk])
print(f”Chunk {i} encoding result:”, encoded) # Debugging statement# Access `input_ids` and `attention_mask` and structure inputs for the model
if ‘input_ids’ in encoded and ‘attention_mask’ in encoded:
input_ids = encoded[‘input_ids’]
attention_mask = encoded[‘attention_mask’]
inputs = {‘input_ids’: input_ids, ‘attention_mask’: attention_mask}
outputs = shiba_model(**inputs)
all_outputs.append(outputs)
encoded_chunks.append(input_ids[0]) # Store input_ids for decodingreturn all_outputs, encoded_chunksStep 6: Decode Tokens Back to Text
After processing, decode the tokenized outputs back into readable text. This step helps verify that the input-output pipeline is functioning correctly.
def decode_tokens(encoded_chunks):
decoded_text = “”
for tokens in encoded_chunks:
decoded_text += tokenizer.decode(tokens)
return decoded_text
Step 7: Test the Implementation
Provide the path to a sample PDF file and process it using the functions defined above. Print the decoded text to verify the result.
# Example usage
pdf_path = “sample.pdf”
outputs, encoded_chunks = process_pdf_with_shiba(pdf_path)
decoded_text = decode_tokens(encoded_chunks)
print(“Decoded Text:”, decoded_text)Final Thoughts
This implementation demonstrates how to integrate SHIBA into an NLP workflow, making it a valuable tool for processing text from PDFs or other sources. With its character-level tokenization and pretrained capabilities, SHIBA excels in handling noisy or unconventional text.
Results:
Input:
“Sample PDF This is a simple PDF file. Fun fun fun. Lorem ipsum dolor sit amet, consectetuer adipiscing elit. Phasellus facilisis odio sed mi. Curabitur suscipit. Nullam vel nisi. Etiam semper ipsum ut lectus. Proin aliquam, erat eget pharetra commodo, eros mi condimentum quam, sed commodo justo quam ut velit. Integer a erat. Cras laoreet ligula cursus enim. Aenean scelerisque velit et tellus. Vestibulum dictum aliquet sem. Nulla facilisi. Vestibulum accumsan ante vitae elit. Nulla erat dolor, blandit in, rutrum quis, semper pulvinar, enim. Nullam varius congue risus. Vivamus sollicitudin, metus ut interdum eleifend, nisi tellus pellentesque elit, tristique accumsan eros quam et risus. Suspendisse libero odio, mattis sit amet, aliquet eget, hendrerit vel, nulla. Sed vitae augue. Aliquam erat volutpat. Aliquam feugiat vulputate nisl. Suspendisse quis nulla pretium ante pretium mollis. Proin velit ligula, sagittis at, egestas a, pulvinar quis, nisl.”
Output:
“Sample PDFThis is a simple PDF file. Fun fun fun.Lorem ipsum dolor sit amet, consectetuer adipiscing elit. Phasellus facilisis odio sed mi. Curabitur suscipit. Nullam vel nisi. Etiam semper ipsum ut lectus. Proin aliquam, erat eget pharetra commodo, eros mi condimentum quam, sed commodo justo quam ut velit. Integer a erat. Cras laoreet ligula cursus enim. Aenean scelerisque velit et tellus. Vestibulum dictum aliquet sem. Nulla facilisi. Vestibulum accumsan ante vitae elit. Nulla erat dolor, blandit in, rutrum quis, semper pulvinar, enim. Nullam varius congue risus. Vivamus sollicitudin, metus ut interdum eleifend, nisi tellus pellentesque elit, tristique accumsan eros quam et risus. Suspendisse libero odio, mattis sit amet, aliquet eget, hendrerit vel, nulla. Sed vitae augue. Aliquam erat volutpat. Aliquam feugiat vulputate nisl. Suspendisse quis nulla pretium ante pretium mollis. Proin velit ligula, sagittis at, egestas a, pulvinar quis, nisl.”
You can checkout more results here: https://drive.google.com/drive/folders/1MFw9jeTG6OS0XW1kzxI5umMiztLFnmEI?usp=sharing
Conclusion
Tokenization is a foundational step in the field of natural language processing (NLP) and large language models (LLMs). It bridges the gap between raw text and the numerical data that models require for computation. An effective tokenizer is essential for ensuring that the input representation is both compact and meaningful, enabling models to learn and infer efficiently.
SHIBA stands out as a highly efficient and versatile tokenizer and model, operating at the character level. Unlike traditional word-based or subword-based tokenizers, SHIBA’s character-level approach eliminates the reliance on pre-defined vocabularies, making it more adaptable to languages with rich morphology, noisy or unconventional text, and low-resource settings. Its character-level tokenization ensures no out-of-vocabulary tokens, which is a common limitation in many word-based models.
In comparison to other tokenizers, SHIBA is approximately four times more efficient while maintaining high accuracy, as demonstrated in text classification and segmentation tasks. It is particularly robust in handling messy or informal text, where dictionary-based tools like MeCab may struggle.
The importance of tokenization in the LLM industry cannot be overstated. It directly impacts a model’s ability to generalize across diverse datasets, adapt to new languages, and maintain computational efficiency. SHIBA exemplifies how innovative approaches to tokenization can enhance model performance, providing a competitive edge in the rapidly evolving NLP landscape.
Official repo of SHIBA– https://github.com/octanove/shiba
Github repo of the code- https://github.com/arnavgupta16/shiba_tokenizer
Linkedin- https://www.linkedin.com/in/arnav-gupta-437a66256/

